Belief Networks (by Koller)
Koller's approach to Belief networks (which she calls [...]) is more intuative than Barber's. Consider the student model:
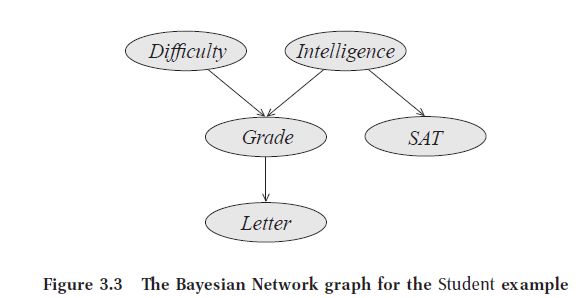
Difficulty: difficulty of a test. Grade: a course grade received by the student. SAT: the student's SAT score. Letter: whether the student's letter of recommendation from the course professor was positive or not. The professor only consults the student's recorded course grade.
Koller proceeds by enumerating the independent assumptions in this model. We can reason that:
The professor's recommendation letter depends only on the student's grade in the class.
This can be expressed as:
[...]In other words, once we know the student's grade, our beliefs about the quality of the recommendation letter are not influenced by information about any of the other variables.
-
The student's SAT score depends only on the student's intelligence:
[...] -
Once we know that [something, something else] gives no additional information towards predicting his grade:
\[ (G \perp S \vert I, D) \] -
Intelligence is independent of the test difficulty:
\[ (I \perp D) \] -
Knowing that [...] does not influence our beliefs in [...]:
\[ (D \perp I, S) \]
Koller describes this whole thing in more detail. She explains how, intuitively, a parent variable "shields" its descendants from probabilistic influence from other variables. Once I know the value of the parents, no information relating directly or indirectly to the parents or other ancestors can influence my beliefs.
With this model in mind, the formal definition follows quite naturally.
Bayesian network, definition
A Bayesian network structure \( G \) is a directed acyclic graph whose nodes represent random variables \( X_1, ..., X_n \). Let \( Pa_{X_i}^G \) denote the parents of \( X_i \) in \( G \), and \( \operatorname{NonDescendants}_{X_i} \) denote the variables in the graph that are not descendants of \( X_i \). Then \( G \) encodes the following set of conditional independence assumptions, called the local independencies, and denoted by \( \mathcal{I}_{l}(G) \):
In other words, the local independencies state that each node \( X_i \) is conditionally independent of its nondescendants given its parents.
For the student case, the independence statements are the 5 above.