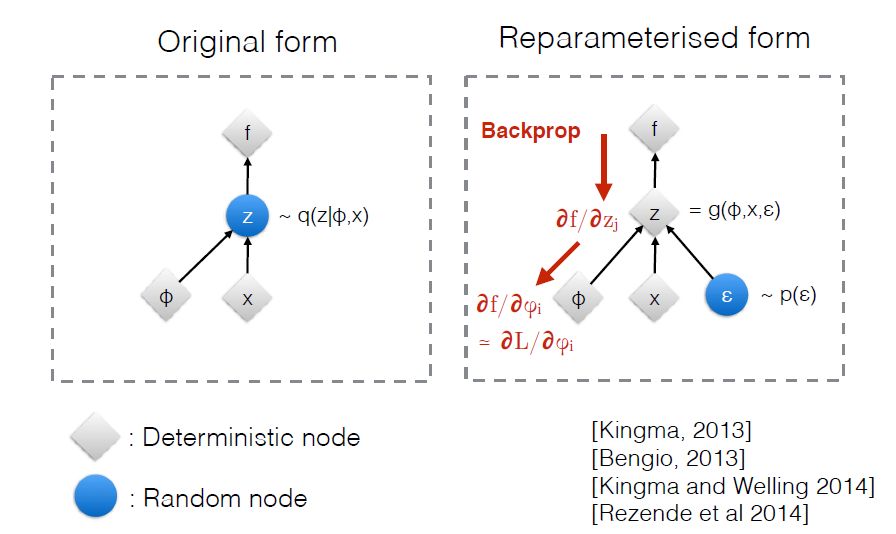
In Karol Gregor's talk [6], e is described as [...] that limits the information passed between the encoder and decoder layers (otherwise μ,Σ, being made up of real numbers, would carry an infinite number of bits). Somehow this prevents similar z being decoded into wildly different images, but I don't fully understand the info-theory interpretation quite yet.
So, the second half of the network will be told to draw "some sort of 6, with certain qualities (x,y,z) that are chosen randomly by e?" I'm not sure I understand.
My distribution collapse perspective on e
If the sampling function \( g(\phi, x, \varepsilon) \) was a normal distribution of some sort, without the randomness, the network could learn to set the variance to zero and propagate whatever value the mean is exactly. This might cause the network to take shortcuts and not learn latent variables. So, the e term gives a restriction to the encoder: you must encode in such a way that can still communicate sufficient information despite your output being purturbed in a very specific way. For the random normal case, the encoded has control of this purturbation by controlling \( \sigma \), however, the encoded is penalized as \( \sigma \) gets further from the value 1.0 (to match a standard normal). I wonder what would happen if you didn't let the encoder produce \( \sigma \) at all and had it hard-coded to 1.0?
In Karol Gregor's talk [6], e is described as "added noise" that limits the information passed between the encoder and decoder layers (otherwise μ,Σ, being made up of real numbers, would carry an infinite number of bits). Somehow this prevents similar z being decoded into wildly different images, but I don't fully understand the info-theory interpretation quite yet.
So, the second half of the network will be told to draw "some sort of 6, with certain qualities (x,y,z) that are chosen randomly by e?" I'm not sure I understand.
My distribution collapse perspective on e
If the sampling function \( g(\phi, x, \varepsilon) \) was a normal distribution of some sort, without the randomness, the network could learn to set the variance to zero and propagate whatever value the mean is exactly. This might cause the network to take shortcuts and not learn latent variables. So, the e term gives a restriction to the encoder: you must encode in such a way that can still communicate sufficient information despite your output being purturbed in a very specific way. For the random normal case, the encoded has control of this purturbation by controlling \( \sigma \), however, the encoded is penalized as \( \sigma \) gets further from the value 1.0 (to match a standard normal). I wonder what would happen if you didn't let the encoder produce \( \sigma \) at all and had it hard-coded to 1.0?